
GxP Lifeline
Deterministic by Design: How Structured JSON and Deterministic AI Are Transforming Life Sciences Manufacturing

MasterControl's approach to AI combines the power of generative tools with the precision of deterministic control.
AI's Promise Meets Regulatory Reality
Artificial intelligence (AI) has captured the imagination of the life sciences industry with its ability to generate human-like text, analyze complex datasets, and automate tedious tasks. Yet for life sciences manufacturers operating under strict U.S. Food and Drug Administration (FDA), EU good manufacturing practice (GMP), and other global regulations, the excitement comes with a reality check: AI systems that produce unpredictable outputs are not just unreliable—they're unusable in regulated environments.
Consider a typical scenario in life sciences manufacturing. A batch manufacturing record (BMR) documents every step of producing a drug product, from raw material specifications to final quality control results. These records often exceed 100 pages, combining typed text, handwritten annotations, equipment readings, quality stamps, and complex calculations. They must be retained for decades and serve as the definitive proof of compliance during regulatory audits. A single missing signature, an incorrect calculation, or a misinterpreted measurement could have serious consequences for patient safety and regulatory standing.
Now imagine using a standard large language model (LLM) to digitize these documents. The AI might extract most of the text correctly, but it could miss a critical calculation, misinterpret a handwritten annotation, or fail to maintain the hierarchical relationship between manufacturing phases and individual steps. The output might look impressive—until a quality reviewer discovers that essential compliance information has been lost or distorted in translation.
This is the fundamental challenge MasterControl set out to solve: how do you harness the power of generative AI while ensuring the deterministic, reliable outputs required for life sciences manufacturers?
Generative Intelligence Under Deterministic Control
MasterControl's approach to AI is built on a simple but powerful principle: Systems with generative tools and deterministic control planes produce deterministic outputs. This isn't just a technical distinction—it represents a fundamentally different philosophy about how AI should function in regulated industries.
Think of it this way: traditional generative AI is like a highly intelligent but somewhat unpredictable assistant. Ask it to summarize a document, and you'll get different summaries each time, with varying levels of detail and accuracy. For writing marketing copy or brainstorming ideas, this creativity is valuable. But for extracting regulated manufacturing data, this variability is unacceptable.
MasterControl's approach combines the flexibility of generative AI with rigid structural controls. The AI can adapt to different document formats, handle unexpected variations, and intelligently interpret complex content, but it must always consistently produce outputs that conform to exact specifications and pass rigorous validation checks.
The Foundation: Structured JSON as the Universal Language
At the heart of MasterControl's approach is JSON (JavaScript Object Notation)—a simple, structured data format. While JSON might seem like a minor technical detail, it's actually the key that unlocks deterministic AI outputs.
Why JSON Matters
JSON provides a clear, unambiguous structure for representing complex information. Instead of producing free-form text that requires human interpretation, MasterControl's AI systems generate JSON that machines can immediately understand, validate, and process. This structure ensures that:
- Critical relationships are preserved. A manufacturing step remains linked to its parent phase, which remains linked to its operational group. Cross-references between procedures stay intact. Calculations maintain their formulas, variables, and acceptable ranges.
- Validation is automatic. Because JSON has a defined structure, automated systems can instantly verify that every required field is present, every calculation is complete, and every reference resolves correctly. There's no need for manual checking to ensure nothing was missed.
- Compliance is built-in. By encoding GMP requirements directly into the JSON schema, MasterControl ensures that extracted data automatically includes all regulatory-required elements. Users can trust that the structure itself enforces compliance.
- Integration is seamless. Structured JSON output can flow directly into MasterControl's manufacturing execution systems, quality management software, and analytics platform without manual reformatting or data entry.
From Paper to Pixels: The Real-World Challenge
A production operator records equipment readings by hand on a pre-printed form, sometimes writing numbers over existing template text. A quality inspector adds their signature and date stamp, partially obscuring underlying content. Process engineers attach printouts from automated equipment, showing data tables and charts. Decades-old photocopies introduce scanned artifacts, shadows, smudges, paper degradation, and more.
Each facility has its own forms, evolved through years of process refinements in silos. Site-specific abbreviations and notation systems proliferate. Tables span multiple pages with inconsistent header repetition. References like "as per above procedure" replace standard numbering.
Generic document extraction tools fail spectacularly on such content. They might capture the text but lose the structure. They might identify tables but misalign the columns. They might extract numbers but miss whether they're measurements, calculations, or acceptable ranges.
The Technical Architecture: How MasterControl Makes It Work
MasterControl's solution combines several sophisticated technologies into a unified workflow that transforms paper documents into pristine structured data.
Intelligent Document Understanding
The first challenge is simply reading these complex documents. MasterControl employs a hybrid approach that combines multiple technologies:
- MarkItDown handles the initial document structure extraction, preserving tables, lists, and formatting hierarchies from digital PDFs. Think of this as the first pass that captures the obvious structure.
- Qwen3-VL-8B, a vision-language model, analyzes the document visually, extracting text from images, understanding complex layouts, and interpreting handwritten annotations. Unlike traditional optical character recognition (OCR) that processes character-by-character, this AI actually "sees" the document much like a human would, understanding context and relationships.
- Tesseract OCR with adaptive configurations serves as a fallback engine, ensuring that even degraded or challenging content gets processed. Multiple configuration passes handle different text layouts and quality levels.
This hybrid approach achieves approximately 85% accuracy on handwritten annotations—far better than traditional OCR—while maintaining near-perfect accuracy on printed text and preserving complex table structures through visual understanding rather than simple text extraction.
Schema-Guided Extraction: Teaching AI to Think in Structure
The approach that enables deterministic outputs is schema-guided extraction. Rather than asking the AI to "extract manufacturing data," MasterControl provides it with an exact template of what the output should look like, defined using TypeScript class structures.
TypeScript proved more effective than JSON Schema or other alternatives because its type system naturally represents the hierarchical relationships in documents. Optional fields, explicit type unions, and inline documentation provide clear constraints without cluttering the schema.
Here's what makes this powerful: the AI doesn't just extract text—it maps unstructured content to specific structural elements. When it encounters a calculation in the document, it knows to create a calculation object with formula, variables, units, and acceptable ranges. When it sees a table, it preserves headers and rows. When it identifies a manufacturing step, it references the correct parent phase and operational group.
The schema includes 11 distinct content types: text, tables, calculations, images, numeric inputs, dates, timestamps, choice fields, pass/fail outcomes, links, and attachments. Each type has specific fields and validation rules. This granularity ensures that semantics—the meaning and relationships that matter for compliance—are preserved in the digital representation.
Parallel Processing for Scale
BMRs in life sciences environments commonly exceed 100 pages. Processing such documents sequentially would take hours. MasterControl's architecture uses parallel processing to reduce execution time from hours to minutes.
The system intelligently chunks documents using greedy sentence-packing with a 3,000-token threshold. This ensures that sentence boundaries are respected for readability while maximizing information density in each chunk. Oversized content like large tables gets split while preserving as much structure as possible.
Multiple workers process chunks simultaneously, each generating structured JSON. The system tracks maximum group IDs across chunks to ensure unique identifiers when combining results. This parallel architecture maintains document coherence despite processing sections independently—deviations noted in one chunk remain properly linked to corrective actions in another chunk.
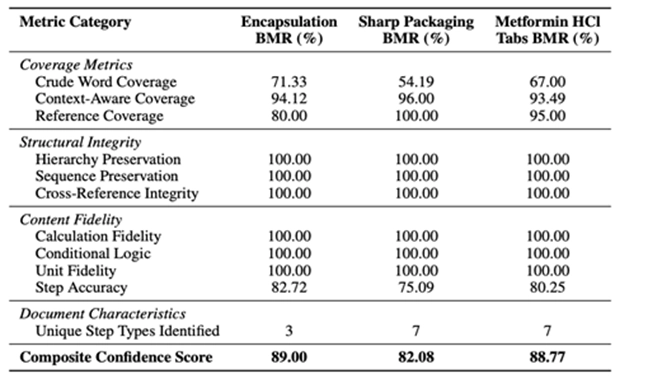
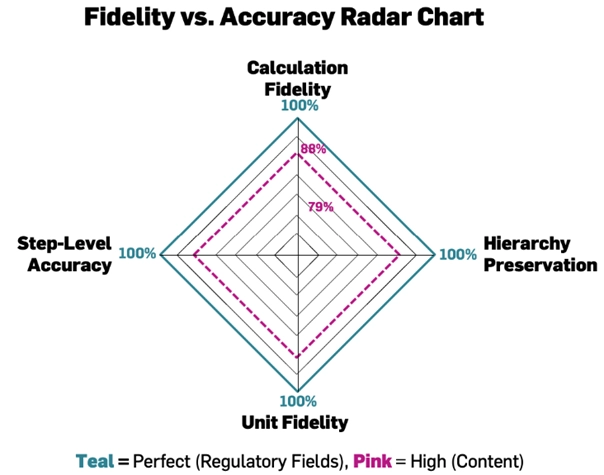
For a typical 66-page BMR, processing drops from several hours of manual quality review to under 32 minutes of automated extraction with 88.77% composite confidence score, maintaining perfect hierarchy preservation and 100% fidelity on calculations, conditional logic, and units—the elements most critical for regulatory compliance.
Real World Results
Triple-Layer Validation: Because One Check Isn't Enough
MasterControl doesn't trust the AI blindly. Every extraction passes through three validation layers:
- Syntactic validation ensures the JSON parses correctly, arrays and objects are well-formed, and reserved tags are used properly. This catches basic structural errors before they propagate.
- Structural validation verifies that phase and step references resolve correctly, sequences match the source document, cross-references are consistent, and the hierarchical relationships are intact. This ensures the document's inherent organization is preserved.
- Validation checks that calculation expressions are valid, units and ranges are well-formed, pass/fail logic is consistent, and all required header fields are populated. This layer encodes GMP requirements directly into the validation logic.
Only extractions that pass all three layers proceed to the next stage. Failures are flagged for human review with specific feedback about what needs correction. This multi-layer approach achieves composite confidence scores of 82%-89% on real-world BMRs while maintaining 100% accuracy on regulatory-critical elements.
ThinkJSON: Taking Schema Adherence Further
Building on the foundation of structured extraction, MasterControl developed ThinkJSON—a reinforcement learning approach that teaches AI models to produce strict, schema-constrained outputs naturally, without requiring extensive prompt engineering or post-processing corrections.
ThinkJSON addresses a fundamental weakness in standard large language models: they excel at free-form text generation but lack intrinsic mechanisms to maintain perfect format adherence. Even with careful prompting, LLMs often produce outputs with missing fields, malformed JSON, or inconsistent key usage. In regulated manufacturing, such deviations aren't just annoying—they break automated pipelines, vitiate digital record integrity, and trigger compliance violations.
The ThinkJSON Innovation
MasterControl's approach combines three key elements:
- Synthetic reasoning datasets pair filled JSON schemas with unstructured text in multiple styles (ASCII tables, PDF snippets, handwritten notes). The system learns not just to extract information but to reason about how unstructured data maps to structured representations.
- Reinforcement learning with GRPO (Group Relative Policy Optimization) trains a 1.5B-parameter model using custom reward functions. The system ranks multiple completions and rewards top performers, teaching the model to consistently produce schema-compliant outputs. Rewards check JSON validity, structural faithfulness, and tag correctness.
- Supervised fine-tuning refines the reinforced model with domain-specific training, ensuring field names are correctly spelled and specialized life sciences terminology is handled properly.
The results speak for themselves: ThinkJSON achieves 62.41% mean field match with just 0.27% unwanted noise—substantially better than alternatives including the original DeepSeek R1 (41.43% match, 11.14% noise) and Gemini 2.0 Flash (42.88% match, 10.86% noise).
Perhaps most impressively, this performance comes from just 20 hours of training on an 8×H100 GPU cluster and three hours on a single A100—demonstrating that strict schema fidelity doesn't require massive computational budgets. This efficiency makes the approach accessible to mid-sized life sciences manufacturers, not just industry giants with unlimited computing resources.
Real-World Impact: From Hours to Minutes, From Risk to Confidence

The true measure of any AI system isn't in benchmark scores but in practical impact. MasterControl's approach delivers tangible benefits across multiple dimensions:
- Time savings. Manual BMR review takes approximately 3 hours per document. With 1,200 BMRs annually at a mid-sized facility, that's 3,600 hours—or 1.7 full-time employees—spent just reviewing batch records. MasterControl's system processes the same documents in minutes to tens of minutes, freeing quality teams for higher-value analysis and decision-making.
- Fidelity where it matters most. The system achieves 100% accuracy on calculations, conditional logic, units, hierarchy, and sequence—exactly the elements with highest regulatory consequence. While crude word coverage might dip to 54% on some documents (often due to site-specific abbreviations), context-aware coverage stays above 93%, meaning essential meaning is always captured.
- Unlocking decades of manufacturing intelligence. Most life sciences companies have archives containing 20,000-plus historical BMRs locked in paper format. Using manual conversion rates of 2-3 documents per person-day, comprehensive digitization would require 27 person-years of effort. MasterControl's automated approach makes this feasible, enabling manufacturers to analyze decades of production data for yield optimization, predictive maintenance, and quality trending analysis.
- Compliance confidence through structure. Because validation is built into the extraction process rather than being a separate manual review step, quality teams can trust that digitized records meet GMP requirements. The structured JSON format automatically includes all required fields, maintains proper relationships, and preserves audit trails.
Looking Forward: The Deterministic AI Advantage
MasterControl's approach to AI represents more than just a technical achievement—it signals a new paradigm for how artificial intelligence should function in regulated industries. The key insight is that generative AI and deterministic outputs aren't contradictory goals. With the right architecture, you can have both the flexibility to handle real-world document variation and the reliability that life sciences manufacturing demands.
This philosophy extends beyond batch record digitization. The same principles—structured outputs, multi-layer validation, schema-guided processing—apply to any scenario where AI must produce reliable, compliant results. Whether it's generating master batch record templates, analyzing deviation reports, or optimizing manufacturing procedures, the combination of generative tools with deterministic control planes ensures outputs that are both intelligent and trustworthy.
MasterControl's structured JSON approach, reinforced through ThinkJSON and validated through real-world BMR processing, demonstrates that you don't have to choose. With the right architecture, AI can be generative and generative tools can produce deterministic outputs that meet the exacting standards of life sciences manufacturing.
To learn more about how MasterControl is applying AI to transform life sciences manufacturing, explore our research at MasterControl AI/ML on Hugging Face or contact us to discuss how structured AI approaches can support your digital transformation journey.

Dr. Rojkova has been building and operating revenue-generating machine learning services and helping companies integrate AI for more than 15 years.
Prior to MasterControl, she led the team of ML and ML Ops engineers at Deloitte to build and support multimodal applications, such as computer vision and predictive maintenance for power and utilities, medical image segmentation, spoken task-oriented language-agnostic dialogue assistants, knowledge graphs, and policy learning for healthcare and life sciences. She also carries ML and NLP experience from Apple, LifeLock/IDAnalytics, and Kernel.
Dr. Rojkova completed her undergraduate degree in neuroscience at Moscow State University before completing a master's degree in psychology and cognitive neuroscience at the University of Illinois- Urbana Champaign and PhD in Computer Science at the University of Louisville. She has authored and co-authored papers and patents in the field of applied AI and ML.

Bhavik Agarwal is a Machine Learning Research Scientist at MasterControl, where he builds dependable Small Language Models (SLMs) and Multi-Agent Systems designed for real-world, regulated production. As the lead author of "From Paper to Structured JSON" (EACL 2026) and "RAGulating Compliance" (International Semantics Web Conference 2025), he specializes in creating agentic workflows that transform complex digital records into verifiable structured data. He is an author of a granted patent and patents in review.
Bhavik’s current research focuses on "ML for Systems"- specifically squeezing maximum performance out of GPUs during LLM pretraining and inference. An alumnus of Johns Hopkins (Masters CS) and IIIT-Delhi (Bachelors CS), Bhavik is also a prominent open-source contributor with over 13 models on Hugging Face.

Nidhi Bendre is an undergraduate student at Northeastern University pursuing a double major in Data Science and Health Science. Her research interests lie at the intersection of machine learning, natural language processing, and biomedical applications. She conducted research under Professor Hamlin on pseudorandom number generator influence on LLM token sampling, which received the PEAK Award. From July to December 2025, she interned as an AI/ML Co-Op at MasterControl, where she developed agentic document processing pipelines for pharmaceutical batch records.